
 M.S. in Mathematics
M.S. in Mathematics I graduated from the School of Mathematics, Southeast University. My research focuses on 3D computer vision, including multimodal foundation models (VLMs and VLAs for embodied intelligence), 3D generative AI (3D AIGC), and the integration of topological data analysis with machine learning. # 
I am fortunate to be advised by Qingshan liu at the Key Laboratory of Collective Intelligence of Cyberspace, Jiangsu Province. Prior to this, I obtained a Bachelor of Applied Mathematics from Guangdong University of Technology.
I am looking for collaborators interested in 3D Computer Vision, Multimodal Foundation Models, and applying these technologies to tasks involving Discrimination👀, Generation🤔, and Action🤖. I believe that deep learning models can effectively leverage multimodal information—such as text, images, point clouds, and topology—to understand complex 3D spatial structures, thereby enhancing their ability for perception, reasoning, and interaction in both physical and virtual environments. If you are interested in collaborating, please feel free to reach out via email or WeChat.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
Southeast UniversityM.S. in MathematicsSep. 2022 - Jul. 2025
-
 Guangdong University of TechnologyB.A. in Applied MathematicsSep. 2018 - Jul. 2022
Guangdong University of TechnologyB.A. in Applied MathematicsSep. 2018 - Jul. 2022
Honors & Awards
-
National Second Prize in Mathematical Modeling for Postgraduate StudentsDec. 2022
-
National Second Prize in Mathematical Modeling for College StudentsSep. 2020
-
Outstanding Graduate AwardJun. 2022
-
Top Ten Young People of Guangdong University of TechnologyJan. 2022
Experience
-
 XpengMultimodal and Computer Vision Intern (Pre-Research Department of the Robotics Center, Human-Computer Interaction and VLA Team)Mar. 2025 - present
XpengMultimodal and Computer Vision Intern (Pre-Research Department of the Robotics Center, Human-Computer Interaction and VLA Team)Mar. 2025 - present -
 MeituanMultimodal and Computer Vision Intern (Basic Research and Development Department, VLA Team)May. 2024 - Sep. 2024
MeituanMultimodal and Computer Vision Intern (Basic Research and Development Department, VLA Team)May. 2024 - Sep. 2024
News
Selected Publications (view all )
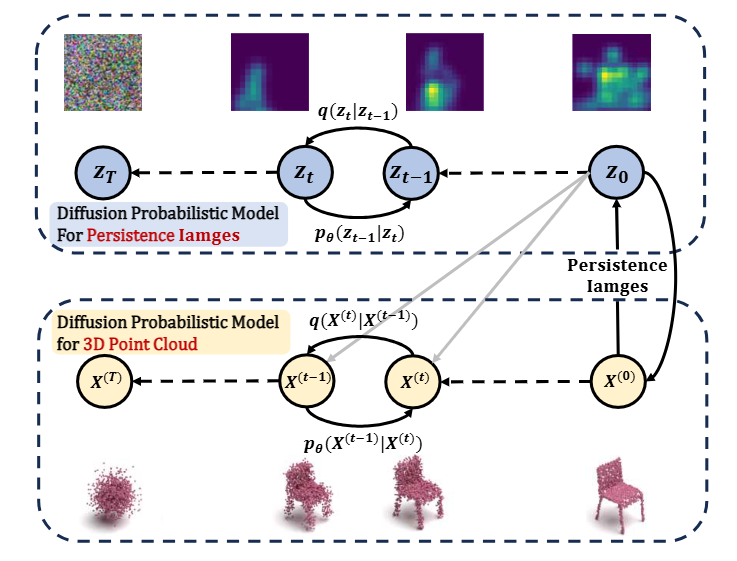
TopoDDPM: Diffusion Probabilistic Models using Persistent Homology for 3D Point Cloud Generation
Zechao Guan*, Shuai Du*, Qingshan Liu# (* equal contribution, # corresponding author)
UnderReview 2025
Recently, diffusion model has emerged as a powerful paradigm for 3D point cloud generation. However, existing methods primarily focus on local geometric features while neglecting global topological features that are critical for structural fidelity, resulting in incomplete structures of the generated results. To address these limitations, we propose TopoDDPM, a novel diffusion probabilistic model that explicitly integrates persistent homology to improve the structural quality of the generated point clouds. Specifically, we introduce a topology latent, extracted by persistent homology, and a shape latent, parameterized through a normalizing flow. These serve as the conditions during the denoising process, enabling the model to learn both geometric and topological characteristics. Additionally, we design a topological loss function to enforce structural consistency throughout the diffusion process. Experimental results on the ShapeNet dataset demonstrate that TopoDDPM outperforms most existing methods in terms of fidelity, diversity, and training efficiency, while better preserving topological integrity. Furthermore, TopoDDPM highlights the importance of rich topological information in improving 3D point cloud generation.
TopoDDPM: Diffusion Probabilistic Models using Persistent Homology for 3D Point Cloud Generation
Zechao Guan*, Shuai Du*, Qingshan Liu# (* equal contribution, # corresponding author)
UnderReview 2025
Recently, diffusion model has emerged as a powerful paradigm for 3D point cloud generation. However, existing methods primarily focus on local geometric features while neglecting global topological features that are critical for structural fidelity, resulting in incomplete structures of the generated results. To address these limitations, we propose TopoDDPM, a novel diffusion probabilistic model that explicitly integrates persistent homology to improve the structural quality of the generated point clouds. Specifically, we introduce a topology latent, extracted by persistent homology, and a shape latent, parameterized through a normalizing flow. These serve as the conditions during the denoising process, enabling the model to learn both geometric and topological characteristics. Additionally, we design a topological loss function to enforce structural consistency throughout the diffusion process. Experimental results on the ShapeNet dataset demonstrate that TopoDDPM outperforms most existing methods in terms of fidelity, diversity, and training efficiency, while better preserving topological integrity. Furthermore, TopoDDPM highlights the importance of rich topological information in improving 3D point cloud generation.

RoboMM: All-in-One Multimodal Large Model for Robotic Manipulation
Feng Yan, Fanfan Liu, Yiyang Huang, Zechao Guan, Liming Zheng, Yufeng Zhong, Chengjian Feng, Lin Ma# (# corresponding author)
Accepted to ICCV 2025
In recent years, robotics has advanced significantly through the integration of larger models and large-scale datasets. However, challenges remain in applying these models to 3D spatial interactions and managing data collection costs. To address these issues, we propose the multimodal robotic manipulation model, RoboMM, along with the comprehensive dataset, RoboData. RoboMM enhances 3D perception through camera parameters and occupancy supervision. Building on OpenFlamingo, it incorporates Modality-Isolation-Mask and multimodal decoder blocks, improving modality fusion and fine-grained perception. RoboData offers the complete evaluation system by integrating several well-known datasets, achieving the first fusion of multi-view images, camera parameters, depth maps, and actions, and the space alignment facilitates comprehensive learning from diverse robotic datasets. Equipped with RoboData and the unified physical space, RoboMM is the first generalist policy that enables simultaneous evaluation across all tasks within multiple datasets, rather than focusing on limited selection of data or tasks. Its design significantly enhances robotic manipulation performance, increasing the average sequence length on the CALVIN from 1.7 to 3.3 and ensuring cross-embodiment capabilities, achieving state-of-the-art results across multiple datasets.
RoboMM: All-in-One Multimodal Large Model for Robotic Manipulation
Feng Yan, Fanfan Liu, Yiyang Huang, Zechao Guan, Liming Zheng, Yufeng Zhong, Chengjian Feng, Lin Ma# (# corresponding author)
Accepted to ICCV 2025
In recent years, robotics has advanced significantly through the integration of larger models and large-scale datasets. However, challenges remain in applying these models to 3D spatial interactions and managing data collection costs. To address these issues, we propose the multimodal robotic manipulation model, RoboMM, along with the comprehensive dataset, RoboData. RoboMM enhances 3D perception through camera parameters and occupancy supervision. Building on OpenFlamingo, it incorporates Modality-Isolation-Mask and multimodal decoder blocks, improving modality fusion and fine-grained perception. RoboData offers the complete evaluation system by integrating several well-known datasets, achieving the first fusion of multi-view images, camera parameters, depth maps, and actions, and the space alignment facilitates comprehensive learning from diverse robotic datasets. Equipped with RoboData and the unified physical space, RoboMM is the first generalist policy that enables simultaneous evaluation across all tasks within multiple datasets, rather than focusing on limited selection of data or tasks. Its design significantly enhances robotic manipulation performance, increasing the average sequence length on the CALVIN from 1.7 to 3.3 and ensuring cross-embodiment capabilities, achieving state-of-the-art results across multiple datasets.
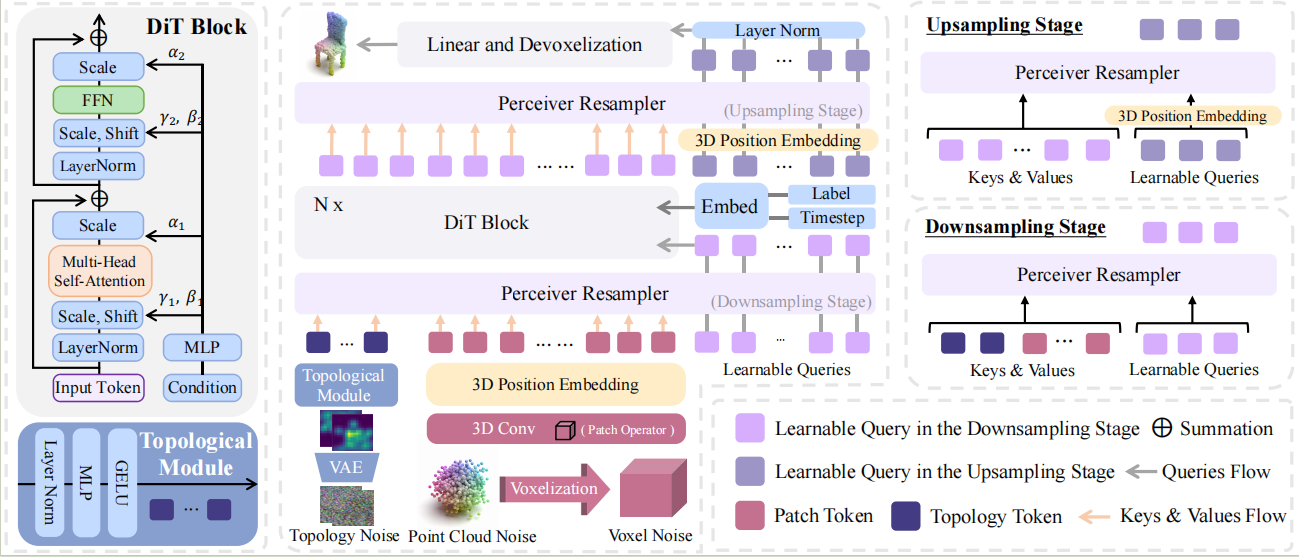
TopoDiT-3D: Topology-Aware Diffusion Transformer with Bottleneck Structure for 3D Point Cloud Generation
Zechao Guan, Feng Yan, Shuai Du, Lin Ma, Qingshan Liu# (# corresponding author)
Accepted to BMVC 2025
Recent advancements in Diffusion Transformer (DiT) models have significantly improved 3D point cloud generation. However, existing methods primarily focus on local feature extraction while overlooking global topological information, such as voids, which are crucial for maintaining shape consistency and capturing complex geometries. To address this limitation, we propose TopoDiT-3D, a Topology-Aware Diffusion Transformer with a bottleneck structure for 3D point cloud generation. Specifically, we design the bottleneck structure utilizing Perceiver Resampler, which not only offers a mode to integrate topological information extracted through persistent homology into feature learning, but also adaptively filters out redundant local features to improve training efficiency. Experimental results demonstrate that TopoDiT-3D outperforms state-of-the-art models in visual quality, diversity, and training efficiency. Furthermore, TopoDiT-3D demonstrates the importance of rich topological information for 3D point cloud generation and its synergy with conventional local feature learning.
TopoDiT-3D: Topology-Aware Diffusion Transformer with Bottleneck Structure for 3D Point Cloud Generation
Zechao Guan, Feng Yan, Shuai Du, Lin Ma, Qingshan Liu# (# corresponding author)
Accepted to BMVC 2025
Recent advancements in Diffusion Transformer (DiT) models have significantly improved 3D point cloud generation. However, existing methods primarily focus on local feature extraction while overlooking global topological information, such as voids, which are crucial for maintaining shape consistency and capturing complex geometries. To address this limitation, we propose TopoDiT-3D, a Topology-Aware Diffusion Transformer with a bottleneck structure for 3D point cloud generation. Specifically, we design the bottleneck structure utilizing Perceiver Resampler, which not only offers a mode to integrate topological information extracted through persistent homology into feature learning, but also adaptively filters out redundant local features to improve training efficiency. Experimental results demonstrate that TopoDiT-3D outperforms state-of-the-art models in visual quality, diversity, and training efficiency. Furthermore, TopoDiT-3D demonstrates the importance of rich topological information for 3D point cloud generation and its synergy with conventional local feature learning.
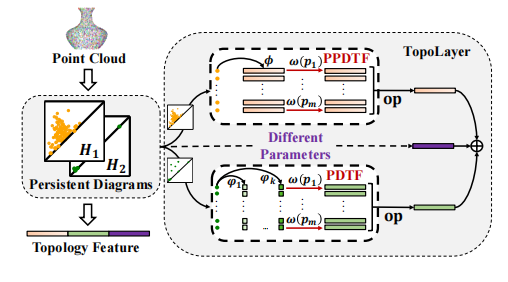
TopoLayer: A Universal Neural Network Layer for Advanced Topology Feature Learning on Point Clouds using Persistent Homology
Zechao Guan, Shuai Du, Qingshan Liu# (# corresponding author)
Accepted to ICME 2025
Point cloud is complex 3D data characterized by its irregularity and unordered structure. In contrast to previous efforts aimed at extracting local geometric information by sophisticated techniques, we delve into the rich topological information of point clouds using persistent homology. First, we introduce two vectorization methods, PPDTF and PDTF, to transform topological information into a format suitable for deep neural networks. Then we propose TopoLayer, a simple but effective and universal neural network layer seamlessly integrated into existing architectures. Integration of TopoLayer, without architectural modifications, significantly improves established models such as PointMLP and PointNet++. For classification on ModelNet40, the class mean accuracy of PointMLP notably improves from 91.3% to 91.8%, surpassing the state-of-the-art PointMixer. Additionally, PointNet++ achieves a remarkable gain of 2.7%. For part segmentation on ShapeNetPart, PointMLP achieves a new state-of-the-art performance with 85.1% Cls.mIoU, while PointNet++ secures a significant 0.9% increase.
TopoLayer: A Universal Neural Network Layer for Advanced Topology Feature Learning on Point Clouds using Persistent Homology
Zechao Guan, Shuai Du, Qingshan Liu# (# corresponding author)
Accepted to ICME 2025
Point cloud is complex 3D data characterized by its irregularity and unordered structure. In contrast to previous efforts aimed at extracting local geometric information by sophisticated techniques, we delve into the rich topological information of point clouds using persistent homology. First, we introduce two vectorization methods, PPDTF and PDTF, to transform topological information into a format suitable for deep neural networks. Then we propose TopoLayer, a simple but effective and universal neural network layer seamlessly integrated into existing architectures. Integration of TopoLayer, without architectural modifications, significantly improves established models such as PointMLP and PointNet++. For classification on ModelNet40, the class mean accuracy of PointMLP notably improves from 91.3% to 91.8%, surpassing the state-of-the-art PointMixer. Additionally, PointNet++ achieves a remarkable gain of 2.7%. For part segmentation on ShapeNetPart, PointMLP achieves a new state-of-the-art performance with 85.1% Cls.mIoU, while PointNet++ secures a significant 0.9% increase.