2026
Beyond Single-Sample: Reliable Multi-Sample Distillation for Video Understanding
Songlin Li, Xin Zhu, Zechao Guan, Peipeng Chen, Jian Yao
UnderReview 2026
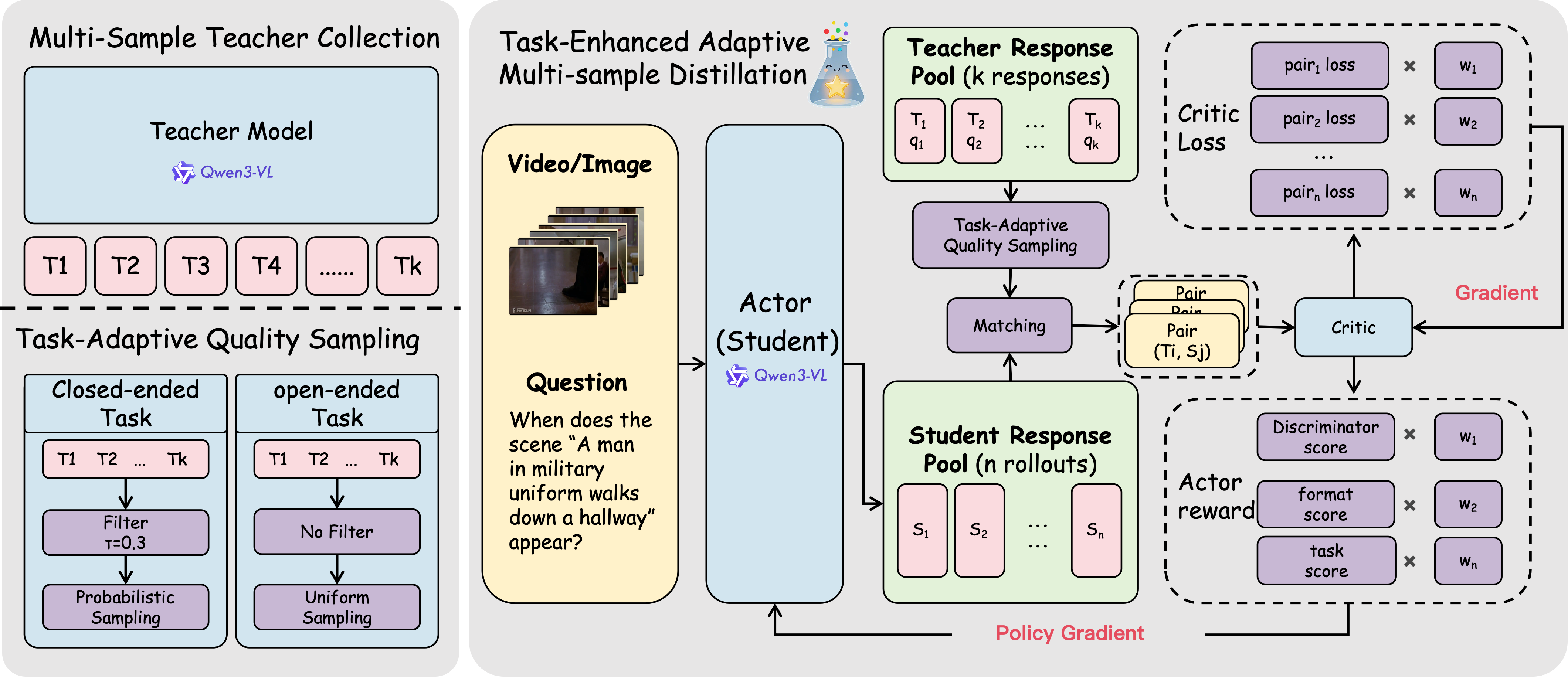
Traditional black-box distillation for Large Vision-Language Models (LVLMs) typically relies on a single teacher response per input, which often yields high-variance responses and format inconsistencies in multimodal or temporal scenarios. To mitigate this unreliable supervision, we propose R-MSD (Reliable Multi-Sample Distillation), a framework that explicitly models teacher sampling variance to enhance distillation stability. Rather than relying on a single teacher response, our approach leverages a task-adaptive teacher pool to provide robust supervision tailored to both closed-ended and open-ended reasoning. By integrating quality-aware signal matching with an adversarial distillation objective, our approach effectively filters teacher noise while maximizing knowledge transfer. Extensive evaluations across comprehensive video understanding benchmarks demonstrate that R-MSD consistently outperforms single sample distillation methods. We additionally include an original SFT+RL 4B baseline under the same training budget, which shows only marginal gains, while our method achieves significant improvements. With a 4B student model, our approach delivers gains on VideoMME (+1.5%), Video-MMMU (+3.2%), and MathVerse (+3.6%).
Beyond Single-Sample: Reliable Multi-Sample Distillation for Video Understanding
Songlin Li, Xin Zhu, Zechao Guan, Peipeng Chen, Jian Yao
UnderReview 2026
Traditional black-box distillation for Large Vision-Language Models (LVLMs) typically relies on a single teacher response per input, which often yields high-variance responses and format inconsistencies in multimodal or temporal scenarios. To mitigate this unreliable supervision, we propose R-MSD (Reliable Multi-Sample Distillation), a framework that explicitly models teacher sampling variance to enhance distillation stability. Rather than relying on a single teacher response, our approach leverages a task-adaptive teacher pool to provide robust supervision tailored to both closed-ended and open-ended reasoning. By integrating quality-aware signal matching with an adversarial distillation objective, our approach effectively filters teacher noise while maximizing knowledge transfer. Extensive evaluations across comprehensive video understanding benchmarks demonstrate that R-MSD consistently outperforms single sample distillation methods. We additionally include an original SFT+RL 4B baseline under the same training budget, which shows only marginal gains, while our method achieves significant improvements. With a 4B student model, our approach delivers gains on VideoMME (+1.5%), Video-MMMU (+3.2%), and MathVerse (+3.6%).
2025
TopoDDPM: Diffusion Probabilistic Models using Persistent Homology for 3D Point Cloud Generation
Zechao Guan*, Shuai Du*, Qingshan Liu# (* equal contribution, # corresponding author)
Accepted to Neural Networks 2026
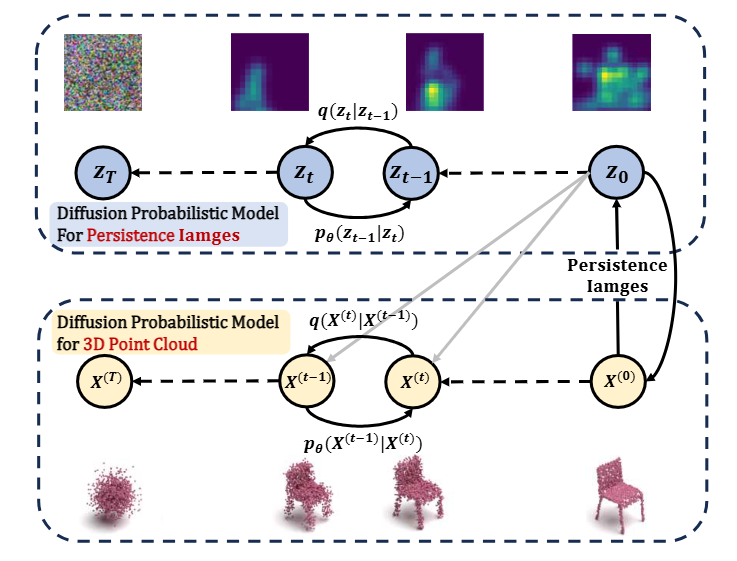
Recently, diffusion-based generative neural networks have emerged as a powerful paradigm for 3D point cloud generation. However, existing methods primarily focus on local geometric features while neglecting global topological features that are critical for structural fidelity, resulting in incomplete structures of the generated results. To address these limitations, we propose the TopoDDPM, a novel diffusion probabilistic model that explicitly integrates persistent homology to improve the structural quality of the generated point clouds. Specifically, we introduce a topology latent, extracted by persistent homology, and a shape latent, parameterized through a normalizing flow. These serve as the conditions during the denoising process, enabling the model to learn both geometric and topological characteristics. Additionally, we design a topological loss function to enforce structural consistency throughout the diffusion process. Experimental results on the ShapeNet dataset demonstrate that the proposed TopoDDPM outperforms most existing methods in terms of fidelity, diversity, and training efficiency, while better preserving topological integrity. Furthermore, TopoDDPM highlights the importance of rich topological information in improving 3D point cloud generation.
TopoDDPM: Diffusion Probabilistic Models using Persistent Homology for 3D Point Cloud Generation
Zechao Guan*, Shuai Du*, Qingshan Liu# (* equal contribution, # corresponding author)
Accepted to Neural Networks 2026
Recently, diffusion-based generative neural networks have emerged as a powerful paradigm for 3D point cloud generation. However, existing methods primarily focus on local geometric features while neglecting global topological features that are critical for structural fidelity, resulting in incomplete structures of the generated results. To address these limitations, we propose the TopoDDPM, a novel diffusion probabilistic model that explicitly integrates persistent homology to improve the structural quality of the generated point clouds. Specifically, we introduce a topology latent, extracted by persistent homology, and a shape latent, parameterized through a normalizing flow. These serve as the conditions during the denoising process, enabling the model to learn both geometric and topological characteristics. Additionally, we design a topological loss function to enforce structural consistency throughout the diffusion process. Experimental results on the ShapeNet dataset demonstrate that the proposed TopoDDPM outperforms most existing methods in terms of fidelity, diversity, and training efficiency, while better preserving topological integrity. Furthermore, TopoDDPM highlights the importance of rich topological information in improving 3D point cloud generation.

RoboMM: All-in-One Multimodal Large Model for Robotic Manipulation
Feng Yan, Fanfan Liu, Yiyang Huang, Zechao Guan, Liming Zheng, Yufeng Zhong, Chengjian Feng, Lin Ma# (# corresponding author)
Accepted to ICCV 2025
In recent years, robotics has advanced significantly through the integration of larger models and large-scale datasets. However, challenges remain in applying these models to 3D spatial interactions and managing data collection costs. To address these issues, we propose the multimodal robotic manipulation model, RoboMM, along with the comprehensive dataset, RoboData. RoboMM enhances 3D perception through camera parameters and occupancy supervision. Building on OpenFlamingo, it incorporates Modality-Isolation-Mask and multimodal decoder blocks, improving modality fusion and fine-grained perception. RoboData offers the complete evaluation system by integrating several well-known datasets, achieving the first fusion of multi-view images, camera parameters, depth maps, and actions, and the space alignment facilitates comprehensive learning from diverse robotic datasets. Equipped with RoboData and the unified physical space, RoboMM is the first generalist policy that enables simultaneous evaluation across all tasks within multiple datasets, rather than focusing on limited selection of data or tasks. Its design significantly enhances robotic manipulation performance, increasing the average sequence length on the CALVIN from 1.7 to 3.3 and ensuring cross-embodiment capabilities, achieving state-of-the-art results across multiple datasets.
RoboMM: All-in-One Multimodal Large Model for Robotic Manipulation
Feng Yan, Fanfan Liu, Yiyang Huang, Zechao Guan, Liming Zheng, Yufeng Zhong, Chengjian Feng, Lin Ma# (# corresponding author)
Accepted to ICCV 2025
In recent years, robotics has advanced significantly through the integration of larger models and large-scale datasets. However, challenges remain in applying these models to 3D spatial interactions and managing data collection costs. To address these issues, we propose the multimodal robotic manipulation model, RoboMM, along with the comprehensive dataset, RoboData. RoboMM enhances 3D perception through camera parameters and occupancy supervision. Building on OpenFlamingo, it incorporates Modality-Isolation-Mask and multimodal decoder blocks, improving modality fusion and fine-grained perception. RoboData offers the complete evaluation system by integrating several well-known datasets, achieving the first fusion of multi-view images, camera parameters, depth maps, and actions, and the space alignment facilitates comprehensive learning from diverse robotic datasets. Equipped with RoboData and the unified physical space, RoboMM is the first generalist policy that enables simultaneous evaluation across all tasks within multiple datasets, rather than focusing on limited selection of data or tasks. Its design significantly enhances robotic manipulation performance, increasing the average sequence length on the CALVIN from 1.7 to 3.3 and ensuring cross-embodiment capabilities, achieving state-of-the-art results across multiple datasets.
TopoDiT-3D: Topology-Aware Diffusion Transformer with Bottleneck Structure for 3D Point Cloud Generation
Zechao Guan, Feng Yan, Shuai Du, Lin Ma, Qingshan Liu# (# corresponding author)
Accepted to BMVC 2025
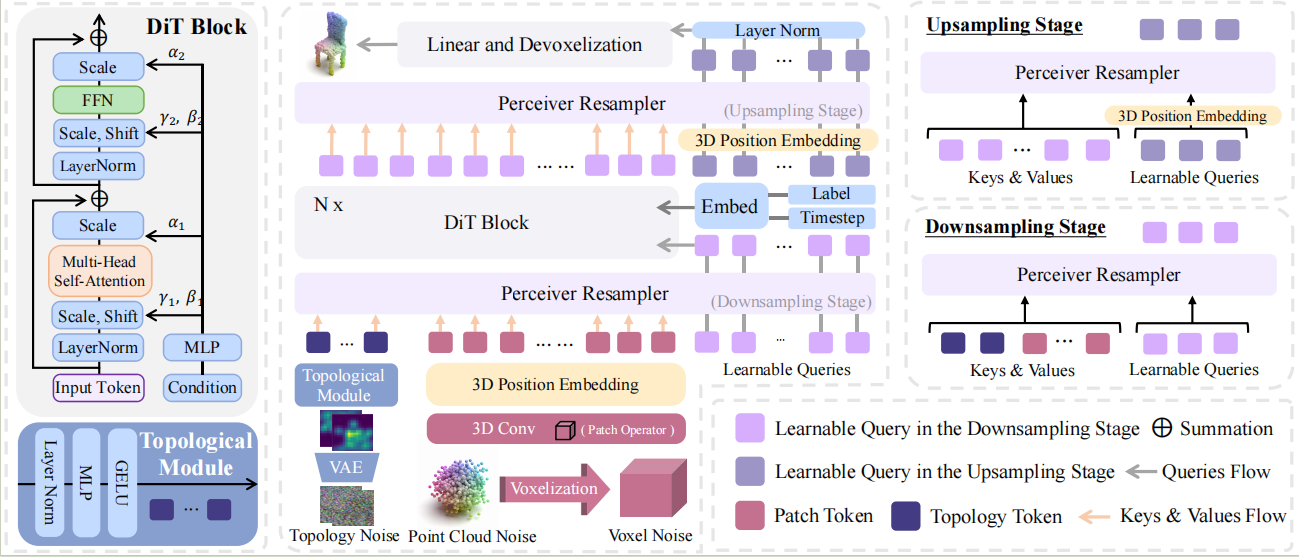
Recent advancements in Diffusion Transformer (DiT) models have significantly improved 3D point cloud generation. However, existing methods primarily focus on local feature extraction while overlooking global topological information, such as voids, which are crucial for maintaining shape consistency and capturing complex geometries. To address this limitation, we propose TopoDiT-3D, a Topology-Aware Diffusion Transformer with a bottleneck structure for 3D point cloud generation. Specifically, we design the bottleneck structure utilizing Perceiver Resampler, which not only offers a mode to integrate topological information extracted through persistent homology into feature learning, but also adaptively filters out redundant local features to improve training efficiency. Experimental results demonstrate that TopoDiT-3D outperforms state-of-the-art models in visual quality, diversity, and training efficiency. Furthermore, TopoDiT-3D demonstrates the importance of rich topological information for 3D point cloud generation and its synergy with conventional local feature learning.
TopoDiT-3D: Topology-Aware Diffusion Transformer with Bottleneck Structure for 3D Point Cloud Generation
Zechao Guan, Feng Yan, Shuai Du, Lin Ma, Qingshan Liu# (# corresponding author)
Accepted to BMVC 2025
Recent advancements in Diffusion Transformer (DiT) models have significantly improved 3D point cloud generation. However, existing methods primarily focus on local feature extraction while overlooking global topological information, such as voids, which are crucial for maintaining shape consistency and capturing complex geometries. To address this limitation, we propose TopoDiT-3D, a Topology-Aware Diffusion Transformer with a bottleneck structure for 3D point cloud generation. Specifically, we design the bottleneck structure utilizing Perceiver Resampler, which not only offers a mode to integrate topological information extracted through persistent homology into feature learning, but also adaptively filters out redundant local features to improve training efficiency. Experimental results demonstrate that TopoDiT-3D outperforms state-of-the-art models in visual quality, diversity, and training efficiency. Furthermore, TopoDiT-3D demonstrates the importance of rich topological information for 3D point cloud generation and its synergy with conventional local feature learning.
TopoLayer: A Universal Neural Network Layer for Advanced Topology Feature Learning on Point Clouds using Persistent Homology
Zechao Guan, Shuai Du, Qingshan Liu# (# corresponding author)
Accepted to ICME 2025
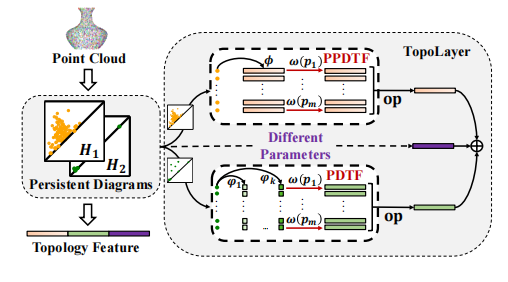
Point cloud is complex 3D data characterized by its irregularity and unordered structure. In contrast to previous efforts aimed at extracting local geometric information by sophisticated techniques, we delve into the rich topological information of point clouds using persistent homology. First, we introduce two vectorization methods, PPDTF and PDTF, to transform topological information into a format suitable for deep neural networks. Then we propose TopoLayer, a simple but effective and universal neural network layer seamlessly integrated into existing architectures. Integration of TopoLayer, without architectural modifications, significantly improves established models such as PointMLP and PointNet++. For classification on ModelNet40, the class mean accuracy of PointMLP notably improves from 91.3% to 91.8%, surpassing the state-of-the-art PointMixer. Additionally, PointNet++ achieves a remarkable gain of 2.7%. For part segmentation on ShapeNetPart, PointMLP achieves a new state-of-the-art performance with 85.1% Cls.mIoU, while PointNet++ secures a significant 0.9% increase.
TopoLayer: A Universal Neural Network Layer for Advanced Topology Feature Learning on Point Clouds using Persistent Homology
Zechao Guan, Shuai Du, Qingshan Liu# (# corresponding author)
Accepted to ICME 2025
Point cloud is complex 3D data characterized by its irregularity and unordered structure. In contrast to previous efforts aimed at extracting local geometric information by sophisticated techniques, we delve into the rich topological information of point clouds using persistent homology. First, we introduce two vectorization methods, PPDTF and PDTF, to transform topological information into a format suitable for deep neural networks. Then we propose TopoLayer, a simple but effective and universal neural network layer seamlessly integrated into existing architectures. Integration of TopoLayer, without architectural modifications, significantly improves established models such as PointMLP and PointNet++. For classification on ModelNet40, the class mean accuracy of PointMLP notably improves from 91.3% to 91.8%, surpassing the state-of-the-art PointMixer. Additionally, PointNet++ achieves a remarkable gain of 2.7%. For part segmentation on ShapeNetPart, PointMLP achieves a new state-of-the-art performance with 85.1% Cls.mIoU, while PointNet++ secures a significant 0.9% increase.